Web页面数据解析处理方法#
urllib3和requests库都是围绕支持HTTP协议实现客户端功能。但是在对页面解析处理上他们可能并不能提供更多的帮助,我们需要借助专门的Web页面数据解析库来解析并提取出结构化结果数据。
Web页面的解析方法通常可以用下面三种方法:
正则表达式 : 将页面当做文本处理,简单直接,大面积撒网。XPath : XPath路径表达式可以让我们像访问目录一样访问Web页面的所有节点元素, 精准匹配。CSS Selector : CSS 选择器Selector 与XPath相似,以CSS样式的表达式来定位节点元素, 精准匹配。
正则表达式#
Python中的正则表达式库re 是我们最为常用的正则库,一条正则表达式可以帮我们过滤掉无用数据,只提取我们需要的格式数据。
在处理网页时,我们并不会频繁的全页面匹配,可想而知这样的效率极低,通常我们需要缩小数据匹配的范围节点,在小范围内进行正则匹配。而缩小范围的方法常常会结合XPath或者Selector一起完成,所以要学会三种方法的配合使用。
有时候,可能一条正则表达式就可以提取出所有我们需要的结果,例如下面这个提取IP:端口的正则表达式:
Python
1
2
3
4
5
6
7
8
9
10
11
| import requests
import re
url = 'https://free-proxy-list.net/anonymous-proxy.html'
r = requests.get(url, timeout=10)
pr_re = r'<td.*?>.*?(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}).*?</td>.*?<td.*?>.*?(\d+).*?</td>'
proxies = re.findall( pr_re, r.text)
proxy_list=[]
for proxy in proxies:
proxy_list.append(':'.join(proxy[0:2]))
print('\n'.join(proxy_list))
|
XPath#
XPath路径表达式可以让我们像访问目录一样访问Web页面的所有节点元素, 精准匹配。
想了解XPath的详细信息,可以阅读XPath快速了解,接下来我们说明下如何在Python中使用XPath
支持XPath的库有lxml、parsel ,其实还有很多,只不过这两个是API接口非常好用的库。
lxml是基于C语言开发库libxml2和libxslt实现的,因此速度上是非常快的(远高于Python自带的ElementTree,所以ElementTree很少被使用)。并且使用cssselect库扩展支持了CSS选择器接口。
parsel则是在lxml基础上的更高级别封装,并且提供了XPath、CSSSelector和re正则表达式三种提取方式的支持,封装的接口也是更加简单易用。同时,parsel也是scrapy所使用的选择器。
lxmlXPath解析示例#
XPath表达式有时候我们不知道如何写时,我们可以通过功浏览器的开发者工具帮助获取XPath,具体方法为:
访问目标URL => 按F12打开开发者模式 => 选择Elementstab页 => 右键要定位的元素 => 选择Copy中的Copy XPath。
如下图所示: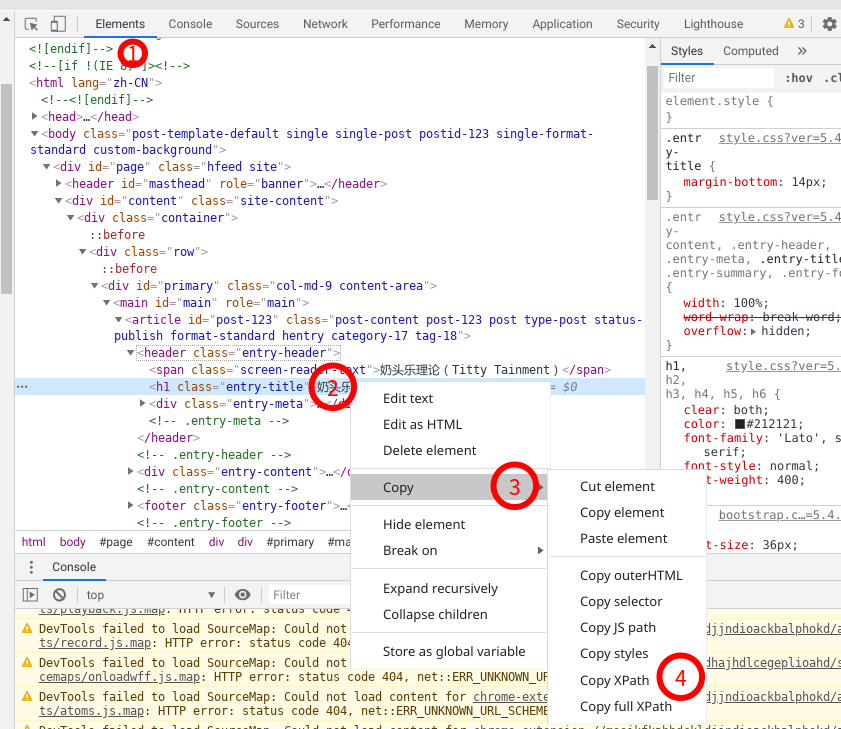
通过此方法得到的XPath,可能很长,或者冗余信息太多,我们只需要在得到的XPath表达式上进行优化即可。
示例一:简单的xpath使用提取博客文章列表#
Python
1
2
3
4
5
6
7
8
9
10
11
| import requests as req
from lxml import etree
url='https://www.learnhard.cn/feed'
resp = req.get(url)
doc = etree.HTML(resp.content)
items = doc.xpath('//item/title/text()')
print('\n'.join(items))
|
示例二:获取微博实时热搜排行榜#
微博实时热搜的cookies信息需要设置一下,不用登录。
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import requests as req
from lxml import etree
import re
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'authority': 'weibo.com',
'cookie': 'UM_distinctid=171437c9856a47-0cd9abe048ffaf-1528110c-1fa400-171437c9857ac3; CNZZDATA1272960323=1824617560-1569466214-%7C1595951362; SCF=AhjAkJNek3wkLok6WSbiibV1WsGffKPYsDlTZtFqiUH_YWL81nk-0xKkiukxpRoDMoIoV0IClwWecgXLLPiBZrw.; SUHB=0gHTlGutSIGq9P; ALF=1628229198; SUB=_2AkMoasG0f8NxqwJRmfoUxG7ibIl_ww7EieKeNjBvJRMxHRl-yT9jqlYktRB6A-rvW2hROYk5DlHgX7r_dk67bcEdfhBN; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWh..ORuiFeK.mEWDWeecX1; SINAGLOBAL=1133654064055.2583.1597394566906; UOR=,,www.comicyu.com; login_sid_t=f855cdd8714fdb25dee824ce5ff8d792; cross_origin_proto=SSL; Ugrow-G0=6fd5dedc9d0f894fec342d051b79679e; TC-V5-G0=4de7df00d4dc12eb0897c97413797808; wb_view_log=1914*10771.0026346445083618; _s_tentry=weibo.com; Apache=4531467438705.743.1597800659782; ULV=1597800659793:3:2:1:4531467438705.743.1597800659782:1597394566920; TC-Page-G0=d6c372d8b8b800aa7fd9c9d95a471b97|1597800912|1597800912; WBStorage=42212210b087ca50|undefined'
}
def main():
url='https://weibo.com/a/hot/realtime'
resp = req.get(url, headers = headers)
doc = etree.HTML(resp.text)
topic_list = doc.xpath('//div[@class="UG_content_row"]')
for topic in topic_list:
desc = topic.xpath('.//div[@class="list_des"]')[0]
topic_title = desc.xpath('h3[@class="list_title_b"]/a/text()')[0].strip()
subinfo = desc.xpath('./div')[0].xpath('string(.)').strip().replace(' ','')
subinfo = re.sub('\s+',',', subinfo)
subinfo = re.findall(r'(.*?),(.*?),.*?([0-9]*?),.*?([0-9]*?),.*?([0-9]+)', subinfo)[0]
print(topic_title + ',' + ','.join(subinfo))
if __name__ == '__main__':
main()
|
运行结果:
sh
1
2
3
4
| python ./demo_weibo_realtime.py
特朗普反击奥巴马夫人,徐子森先生,今天11:39,10,54,11789
...
迪丽热巴广州,芒果娱乐,今天21:30,1786,2600,31562
|
parselXPath解析示例#
我们以微博实时热门关键词为例:
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| import requests as req
from parsel import Selector
import re
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'authority': 'weibo.com',
'cookie': 'UM_distinctid=171437c9856a47-0cd9abe048ffaf-1528110c-1fa400-171437c9857ac3; CNZZDATA1272960323=1824617560-1569466214-%7C1595951362; SCF=AhjAkJNek3wkLok6WSbiibV1WsGffKPYsDlTZtFqiUH_YWL81nk-0xKkiukxpRoDMoIoV0IClwWecgXLLPiBZrw.; SUHB=0gHTlGutSIGq9P; ALF=1628229198; SUB=_2AkMoasG0f8NxqwJRmfoUxG7ibIl_ww7EieKeNjBvJRMxHRl-yT9jqlYktRB6A-rvW2hROYk5DlHgX7r_dk67bcEdfhBN; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWh..ORuiFeK.mEWDWeecX1; SINAGLOBAL=1133654064055.2583.1597394566906; UOR=,,www.comicyu.com; login_sid_t=f855cdd8714fdb25dee824ce5ff8d792; cross_origin_proto=SSL; Ugrow-G0=6fd5dedc9d0f894fec342d051b79679e; TC-V5-G0=4de7df00d4dc12eb0897c97413797808; wb_view_log=1914*10771.0026346445083618; _s_tentry=weibo.com; Apache=4531467438705.743.1597800659782; ULV=1597800659793:3:2:1:4531467438705.743.1597800659782:1597394566920; TC-Page-G0=d6c372d8b8b800aa7fd9c9d95a471b97|1597800912|1597800912; WBStorage=42212210b087ca50|undefined'
}
def main():
url='https://weibo.com/a/hot/realtime'
resp = req.get(url, headers = headers)
# print(resp.text)
selector = Selector(resp.text)
topic_list = selector.xpath('//div[@class="UG_content_row"]')
for topic in topic_list:
desc = topic.xpath('.//div[@class="list_des"]')
topic_title = desc.xpath('h3[@class="list_title_b"]/a/text()').get().strip()
subinfo = desc.xpath('./div').xpath('string(.)').get().strip().replace(' ','')
subinfo = re.sub('\s+',',', subinfo)
subinfo = re.findall(r'(.*?),(.*?),.*?([0-9]*?),.*?([0-9]*?),.*?([0-9]+)', subinfo)[0]
print(topic_title + ',' + ','.join(subinfo))
if __name__ == '__main__':
main()
|
与lxml的示例比较可以发现,两者使用方法非常相近,parsel的xpath()方法每次返回的都是SelectorList对象实例,当需要提取节点值时使用get()或者getall()方法解析,前者返回单个值,而后者返回一个列表,及时只有一个结果也会返回列表。
CSSSelector#
CSS是HTML页面的样式描述语言,CSS选择器其实就是用样式特征来定位元素。
关于CSS选择器详细语法可以阅读 CSS选择器参考手册 这一节。
在你掌握了CSS选择器语法后,接下来就来了解如何在Python中使用它。
Python中支持CSS选择器的库包含了lxml和parsel和pyquery,他们内部都是依赖于cssselect库实现。cssselect库原本是lxml的一个模块,后来独立成为一个项目,但我们依然可以在lxml.cssselect中使用它。
支持CSS选择器的库还有bs4, bs4依赖 soupsieve库实现CSS选择器功能。
同样的,我们以示例作为学习参考来了解如何使用CSS选择器。
lxml中的CSS选择器用法#
通过调用cssselect()方法使用CSS选择器表达式,如下面示例用于提取博客文章列表信息:
Python
1
2
3
4
5
6
7
8
9
10
11
12
| import requests as req
from lxml import etree
url='https://www.learnhard.cn'
resp = req.get(url)
doc = etree.HTML(resp.content)
title_list = doc.cssselect('article > header > h2 > a')
for item in title_list:
title = item.xpath('string(.)').strip()
url = item.xpath('./@href')[0]
print(f'- [{title}]({url})')
|
bs4中的CSS选择器用法#
通过调用select()方法使用CSS选择器表达式,如下面示例用于提取博客文章列表信息:
Python
1
2
3
4
5
6
7
8
9
10
11
12
| import requests as req
from bs4 import BeautifulSoup as bs
url='https://www.learnhard.cn'
resp = req.get(url)
soup = bs(resp.content, 'lxml')
item_list = soup.select('article > header > h2 > a')
for item in item_list:
title = item.get_text().strip()
# url = item.attrs['href']
url = item['href']
print(f'- [{title}]({url})')
|
bs4可以让我们访问一个实例的属性一样来访问标签元素及其属性信息,如本例中我们获取url地址时是通过item.a['href']获取当前元素下<a>标签中@href属性值。
pyquery中的CSS选择器用法#
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
| import requests as req
from pyquery import PyQuery as pq
url='https://www.learnhard.cn'
resp = req.get(url)
query = pq(resp.content)
item_list = query('article > header > h2 > a')
for item in item_list:
title = item.text
url = item.attrib['href']
print(f'- [{title}]({url})')
|
parsel中的CSS选择器用法#
Python
1
2
3
4
5
6
7
8
9
10
11
12
| import requests as req
from parsel import Selector
url='https://www.learnhard.cn'
resp = req.get(url)
sel = Selector(resp.text)
title_list = sel.css('article > header > h2 > a')
for item in title_list:
title = item.css('::text').get()
url = item.css('::attr("href")').get()
# url = item.attrib['href']
print(f'- [{title}]({url})')
|
看到这里,你会发现parsel的文本和属性被当做(伪)节点处理了,这与其他的处理方式都不同,但是这样的好处也显而易见,我们处理属性和文本变得更加直观容易了。
关于CSS选择器需要说明的是,多数的伪类和伪元素选择器是不支持的,例如p:first-child 和 p::first-line。虽然如此,支持的CSS选择器已经提供了足够的功能。cssselect的文档中有详细说明Supported selectors。
另外cssselect支持一些不在CSS规范中的选择器:
:contains(text)伪类选择器[foo!=bar]中的!=属性操作符,等同于:not([foo=bar])。:scope 允许访问选择器的直接子级, 但是必须放在最开头位置, :scope > div::text- 命名空间的用法
ns|div
~END~